It has no real-world application, as no one really trains on dirty data and then test on clean data, but it is interesting to see the effects of data augmentations on the performance of CNN models.
Both PlantDoc and PlantVillage datasets are available on Kaggle:
Data Augmentations?
Data Augmentation
In case you don’t know what data augmentation means
According to this paper by Alhassan Mumuni and Fuseini Mumuni
- The main goal of data augmentation is to increase the volume, quality and diversity of training data
The best practice when it comes to applying data augmentations is to apply them on-the-go, instead of applying the data augmentations and saving the datasets separately. But, I did exactly that (augmenting and saving them externally). This specific approach is not exactly the best, but it did save me memory and time on preprocessing and training.
But why is this distinction (on-the-fly vs static) important to make?
The choice between offline and online data augmentation is dependent on the time and the computing power that you possess, and the amount of variations that you want to have.
For maximum variation, online augmentation works best; but if you lack computing power to perform complex augmentations on large datasets on the fly, offline augmentation helps by processing the images beforehand, reducing training bottlenecks and preventing memory errors.
Nonetheless, storage sizes and computing power shouldn’t be issue as cloud platforms exists [Kaggle, Google Colab, AWS Sagemaker], so you really should opt for online data augmentation as the default.
And as for why this wasn’t the case for this project… well, you’ll see
So, what happens when you stack data augmentations?
As mentioned earlier, this project explores what happens when data augmentations is applied repeatedly, and how different augmentation factors affect model performance.
The augmentations were stacked in the following:
There really wasn’t any particular reason as to why these factors (I’ll call them factors now) were chosen. I felt that they are spaced enough to cover sufficient grounds, but not narrow enough that I recorded meaningless micro-progression.
It’s basically a play on probability, at least that’s how I see it.
But, why is that?
Something that we have to keep in mind is that data augmentation is applied at random. If you think that applying seed to the environment eliminates the randomness, you are misunderstanding the seeding in the first place. Seeding ensures that the experiment is reproducible across multiple sessions; it does not eliminate the randomness within the session itself.
Yes, the same augmentations will be applied, but the augmentations applied were random in the first place. Applying a seed meant fixing the “random”.
Rant aside, we have to look at the result of the data augmentation before proceeding further. Please note that I am cherry-picking the result for the sake of examples
| Example One | Example Two |
|---|---|
 |  |
Both examples here show two instances where the data augmentation () is effective. The noise (hands and pots) are effectively removed from the images. Now, imagine stacking this multiple times; it may completely distort the image, not only removing non-plant morphology, but also the leaves themselves.
Obviously there are cases where the data augmentation missed the mark:
| Failed |
|---|
 |
The random cropping missed the berry, and the fingers are still in the image. Cases such as this is where compounding the augmentation may assist in removing noises.
With that said, the factor determines the amount of times the “random” data augmentations are applied; and as the factor increases, the same image is exposed to more rounds of random transformation. So, if it’s , it means that data augmentation is applied three times onto the same dataset consecutively.
The hypothesis is that at higher augmentation factors, such as and , may eventually reduce model performance because repeated transformations can distort the original plant morphology.
Results
I’ll spare detailed explanation about training, but I will put the configurations in a callout block below
I couldn't get the data augmentation seeding to work
Upon discovering that, I should have ran the pipeline multiple times and then average the results, but I didn’t because it will take way too long on free compute and storage.
Training Configurations
Model trained:
- EfficientNetV2
- Swin Transformer
- A combination of the two
Batch size: 32
Epoch: 100
Early stopping: 10
Learning rates:
- Backbone:
- Head:
Optimiser: AdamW
Scheduler: Linear followed up by cosine decay
So, what’s the outcome?
I was entirely wrong. Well, it could be that the augmentation factors are still not that big to cause major distortion; however, some observations can still be made.
As you go on, keep this quote by Ronald Coase in mind, If you torture the data long enough, it will confess.
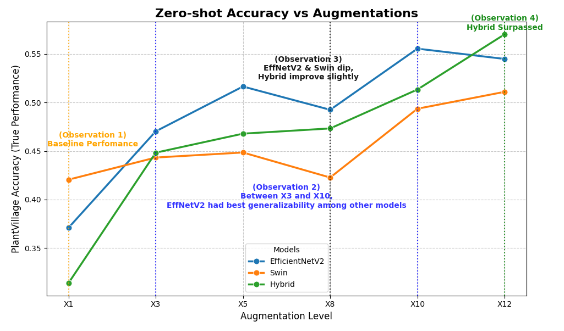
Observation 1
At , the Swin model (0.42) shows a strong baseline performance in cross-dataset generalisation, followed by EfficientNetV2 (0.37) and Hybrid (0.31). This may be due to the transformer’s global attention design, enabling Swin to separate background noise from leaf structures using image-wide context, allowing it to focus directly on leaf pathology with fewer augmentation and samples.
Observation 2
Between and , EfficientNetV2 tops other models with a gradual increment in accuracy, peaking at 0.56; however, at , the model accuracy fell to 0.54, which isn’t something to raise alarms about; it could be due to the randomness that occurred.
My seeding didn’t work, which is strange
Despite the dip, the model demonstrated strong generalisability and stable performance at a moderate augmentation factor. The EfficientNetV2 architecture is optimised for spatial information, so the high augmentation level () may have caused overly aggressive distortions on the samples. Consequently, this disrupts the local spatial rules that the EfficientNetV2 relied on, causing it to lose cues of the diseases amongst the noises.
Or it’s very likely that this is just one of the many variations of the randomness.
Observation 3
At , EfficientNetV2 (-2.40) and Swin (-2.58) models show significant dip while Hybrid (+0.54) shows slight improvement compared to . This indicates that at , the augmentations introduced distortions that disrupted EfficientNetV2 and Swin models. The hybrid model may have just brute forced its way through the distortions.
Or, it’s entirely possible that the augmentations for this particular run is lucky, managing to remove the noises without distorting the important features as much.
Observation 4
The Hybrid model exhibits a steady performance increase across augmentation levels, at , the Hybrid (+5.69) model showed a significant performance gain, increasing from 0.51 to 0.57. The model surpassed the peak performance of EfficientNetV2 ( and model), possibly indicating that Hybrid architecture scales most effectively with higher data augmentations, given its high parameter count.
I am not ruling out the possibility that the run simply was lucky, but models with higher parameter counts are observed to be have performance in complex tasks
Conclusion and Takeaway
This isn’t exactly a slam dunk of a finding on cross-dataset generalisation because of the glaring failed seeding problem that I just couldn’t fix and the dirty to clean dataset approach is just not applicable to real life.
However, it does teach us a couple of things:
- Data augmentations do have a positive effect in the performance of the model, especially when the dataset is dirty
- Static data augmentation, albeit discouraged, does have its place.
- I won’t be doing it any time soon though
- The results become difficult to interpret at a fine-grained level when seeding is not implemented properly, since small differences between augmentation factors may be caused by randomness rather than the augmentation factor itself.
- BUT, I would still argue that it lets us see the overall trend present in the result.
- Nonetheless, multiple runs should have been made.
- BUT, I would still argue that it lets us see the overall trend present in the result.
All in all, this is a short experiment to study the effects of data augmentations and cross-dataset generalisation. Let me know what you think: here or here
Honestly, in hindsight, I should have picked better a pair of datasets; it would have saved me all the headaches.
Announcement